II Essential numerics of hyperbolic PDEs
1 Continuity equation and applications
1.1 Continuity equation
1.2 Examples of hyperbolic systems
1.2.1 Shallow water equations
1.2.2 Euler equations
2 Discontinuous Galerkin discretization
2.1 Grid generation
2.2 Triangle reference and world space
2.3 Basis functions
2.3.1 Nodal basis functions
2.3.2 Modal basis functions
2.4 Weak formulation
2.5 Mass matrix
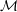
2.6 Stiffness matrices
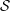
2.7 Flux matrices
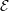
2.8 Source term
2.9 Rotational invariancy and edge space
2.10 Numerical flux
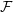
2.10.1 Rusanov flux
2.10.2 Limiter
2.11 Boundary conditions
2.11.1 Dirichlet & Inflow
2.11.2 Outflow
2.11.3 Bounce back
2.12 Adaptive refining and coarsening matrices
 and
and 
2.12.1 Coefficient matrix
2.12.2 Affine transformations to and from the child space
2.12.3 Prolongation to child space
2.12.4 Restriction to the parent space
2.12.5 Adaptivity based on error indicators
2.13 CFL stability condition
2.14 Time stepping schemes
III Efficient framework for simulations on dynamically adaptive grids
3 Requirements and related work
3.1 Simulation: grid, data and communication management
3.2 HPC requirements
3.3 Space-filling curves
3.4 Related work
3.4.1 Dynamic mesh partitioning
3.4.2 Simulation software including grid generation
3.4.3 Related software development
3.4.4 Impact on and from related work
4 Serial implementation
4.1 Grid generation with refinement trees
4.2 Stacks
4.3 Stack-based communication
4.3.1 SFC-labeled grid generation
4.3.2 Communication access order and edge types
4.3.3 Edge-based communication and edge-buffer stack
4.3.4 Vertex-based communication
4.4 Classification of data lifetime
4.5 Stack- and stream-based simulation on a static grid
4.5.1 Required stacks and streams
4.5.2 DG simulation with stacks and streams
4.5.3 Non-destructive streams
4.6 Adaptivity
4.6.1 Refinement
4.6.2 Coarsening
4.6.3 Termination of adaptivity traversals
4.7 Verification of stack-based edge communication
4.8 Higher-order time stepping: Runge-Kutta
4.9 Software design, programmability and realization
4.9.1 Framework and application layer
4.9.2 Simulation driver
4.9.3 Grid traversals and kernels
4.9.4 Kernel interfaces
4.9.5 Code generator
4.10 Optimization
4.10.1 Parameter unrolling
4.10.2 Recursive grid traversal and inlining
4.10.3 Adaptivity automaton
4.10.4 CPU SIMD optimizations for inter-cell computations (fluxes)
4.10.5 Structure of arrays for cell-local computations
4.10.6 Prospective stack allocation
4.11 Contributions
5 Parallelization
5.1 SFC-based parallelization methods for DAMR
5.1.1 SFC-based domain partitioning
5.1.2 Shared- and replicated-data scheme
5.1.3 Partition scheduling
5.2 Inter-partition communication and dynamic meta information
5.2.1 Grid traversals with replicated data layout
5.2.2 Properties of SFC-based inter-partition communication
5.2.3 Meta information for communication
5.2.4 Vertices uniqueness problem
5.2.5 Exchanging communication data and additional stacks
5.2.6 Dynamic updating of run-length-encoded adjacency information
5.3 Parallelization with clusters
5.3.1 Cluster definition
5.3.2 Cluster-based framework design
5.3.3 Cluster set
5.3.4 Cluster unique ids
5.4 Base domain triangulation and initialization of meta information
5.4.1 Initial communication meta information
5.5 Dynamic cluster generation
5.5.1 Splitting
5.5.2 Joining
5.5.3 Split and join updates of meta communication information
5.5.4 Reconstruction of vertex communication meta information
5.6 Shared-memory parallelization
5.6.1 Scheduling strategies
5.6.2 Cluster generation strategies
5.6.3 Threading libraries
5.7 Results: Shared-memory parallelization
5.8 Cluster-based optimization
5.8.1 Single reduce operation for replicated data
5.8.2 Skipping of traversals on clusters with a conforming state
5.8.3 Improved memory consumption with RLE meta information
5.9 Results: Long-term simulations and optimizations on shared-memory
5.10 Distributed-memory parallelization
5.10.1 Intra- and inter-cluster communication
5.10.2 Dynamic cluster generation
5.10.3 Cluster-based load balancing
5.10.4 Distributed base triangulation
5.10.5 Similarities with parallelization of block-adaptive grids
5.11 Hybrid parallelization
5.12 Results: Distributed-memory parallelization
5.12.1 Small-scale distributed-memory scalability studies
5.12.2 Large-scale distributed memory strong-scalability studies
5.13 Summary and Outlook
6 Application scenarios
6.1 Prerequisites
6.1.1 GeoClaw solver
6.1.2 Error norm
6.1.3 Error indicator
6.1.4 Refinement and coarsening with bathymetry
6.2 Analytic benchmark: solitary wave on composite beach
6.2.1 Scenario description
6.2.2 Gauge plots and errors
6.2.3 Dynamic adaptivity
6.3 Field benchmark: Tohoku Tsunami simulation
6.4 Output backends
6.4.1 VTK file backends
6.4.2 OpenGL
6.5 Simulations on the sphere
6.6 Multi-layer simulations
6.7 Summary and outlook
IV Invasive Computing
7 Invasive Computing with invasive hard- and software
7.1 Inavsive hardware architecture
7.2 Invasive software architecture
7.3 Invasive algorithms
7.4 Results
8 Invasive Computing for shared-memory HPC systems
8.1 Invasion with OpenMP and TBB
8.2 Invasive client layer
8.2.1 Constraints
8.2.2 Communication to resource manager
8.2.3 Invasive Computing API
8.3 Invasive resource manager
8.4 Scheduling decisions
8.5 Invasive programming patterns
8.5.1 Iteration-based simulation
8.5.2 Iteration-based with owner-compute
8.6 Results
8.6.1 Micro benchmarks of invasive overheads
8.6.2 Dynamic resource redistribution with scalability graphs
8.6.3 Invasive Tsunami parameter studies
9 Conclusion and outlook
V Summary
A Appendix
A.1 Hyperbolic PDEs
A.1.1 Gauss Lobatto Points
A.1.2 Jacobi polynomials
A.1.3 Mass Matrix
A.1.4 Stiffness matrices
A.1.5 Flux matrices
A.1.6 Butcher tableau
A.1.7 Rotational invariance of Euler equations
A.2 Test platforms
A.2.1 Platform Intel
A.2.2 Platform AMD
A.2.3 Platform MAC Cluster