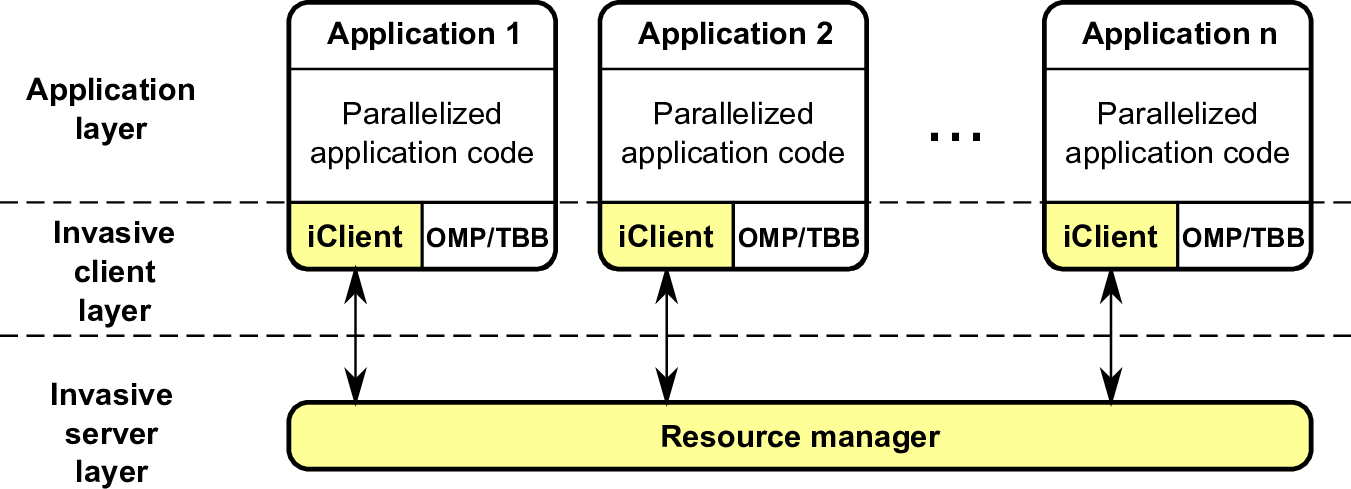
Figure 8.1: Overview of Invasive Computing layers on shared-memory system. Each application
is extended by a client layer adopting the resources and communicating with the resource
manager.
Our Invasive Computing extensions are build on existing functionality of OpenMP1 and Intel TBB2 . Both parallelization models offer parallelization via pragma language extensions or via embedding into the C++ language with a library, respectively. A parallelization on shared-memory has similar restrictions compared to distributed-memory systems which are not considered in HPC standard threading libraries so far:
The applications considered in this work are based on time-stepping schemes. Here, we assume a loop, iterating over the time steps required for the simulation and the parallelization only inside the loop. Due to insufficiencies of OpenMP and TBB to change the number of threads inside a parallel region (see e.g. [Ope08] for OpenMP), we allow changes of threads only at the very beginning of each loop, thus only between each simulation time step. To support invasion of cores, we then have to (a) change the number of threads capable of work stealing and (b) set the pinning of the work stealing threads to physical compute cores.
We only update the number of active threads in each application and their pinning to cores every time if there’s a change in resources either in the number of threads or their pinning.
Considering the previously mentioned requirements, this leads to a software design presented in Fig. 8.1. This extends each application with an invasive client layer which offers the invasive commands which are discussed in the next section. OpenMP and TBB are supported by this client-side extension. The resource manager then orchestrates the resources for all registered invasive applications.