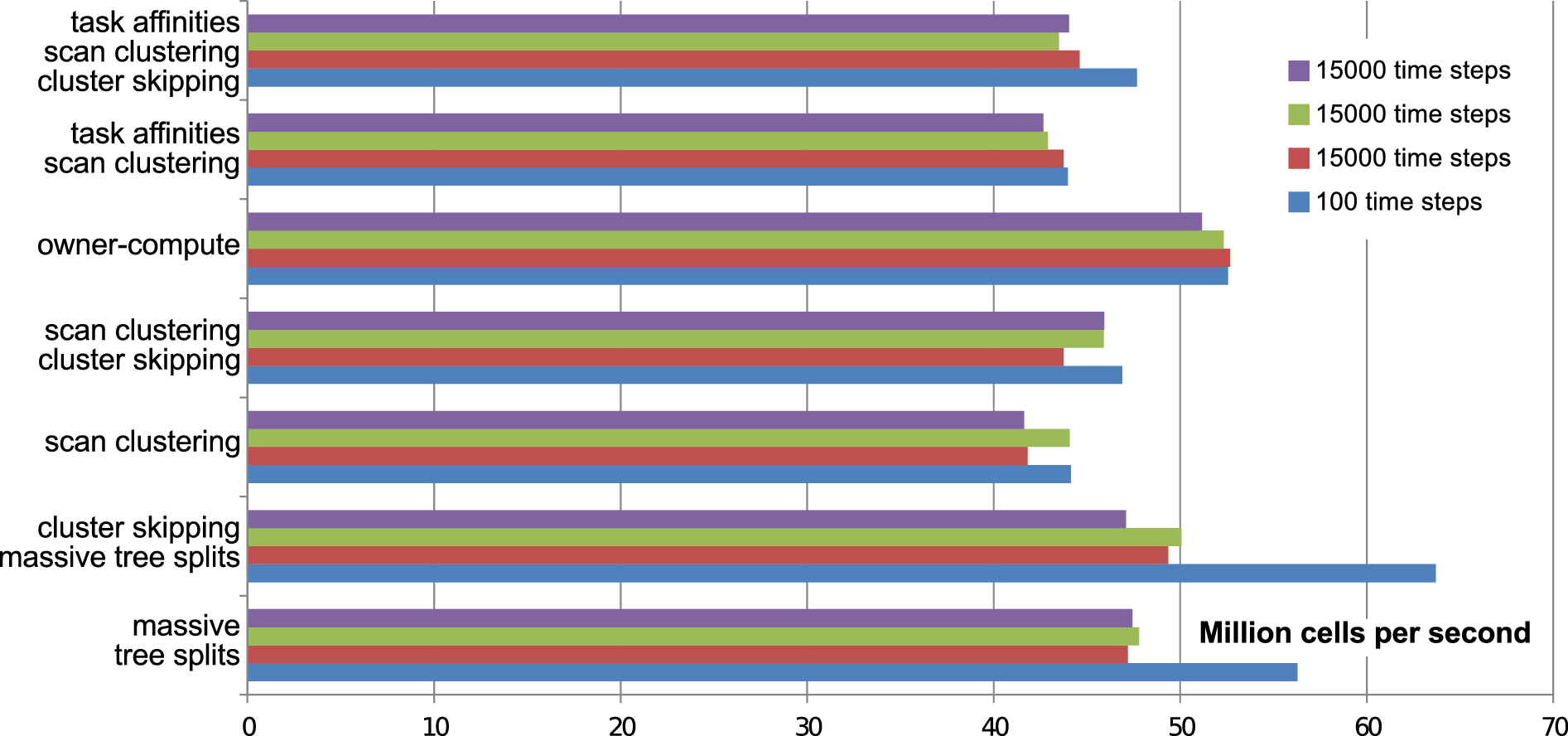
Figure 5.34: Overview of runtimes for simulations with different cluster-generation strategies
with and without skipping of adaptive conforming clusters [SWB13a].
In the previous sections, we conducted several benchmark experiments based on different cluster generation apporaches, affinities and optimizations. However, these benchmarks did not outline possible effects of long-term simulations. Therefore, we conducted long-term simulation runs with 15000 time steps and surveyed different cluster generation, computation scheduling and optimization strategies on our test platform Intel (see Appendix A.2). Such a long-term simulation run also induces more grid changes compared to the short-term run, and thus, also more cluster generations.
For a better comparison, the benchmark scenario is identical with the one already used in Sections 5.7 and 5.8.2. We present the results of cells processed in average per second in Fig. 5.34. Due to the longer run time of 15000 time steps, we also expect an increased noise in the simulation run time. Therefore, we execute the long-term simulation three times.
With our benchmark results at hand, we first search for the formerly best choice, the cluster skipping with the massive tree splitting, which provides the best short-term simulation performance with 100 time steps. However, for long-term simulation runs, the best performance is not anymore provided by this so far best choice: the owner-compute scheme pays off the work stealing mechanism. We account for this by the additional grid changes, causing more cluster generations. With the owner-compute scheme, the clusters are generated in a memory-locality preserving way.
Since the owner-compute scheme also outperforms the affinities using TBB, this scheme is the best choice for long-term simulations for this benchmark.