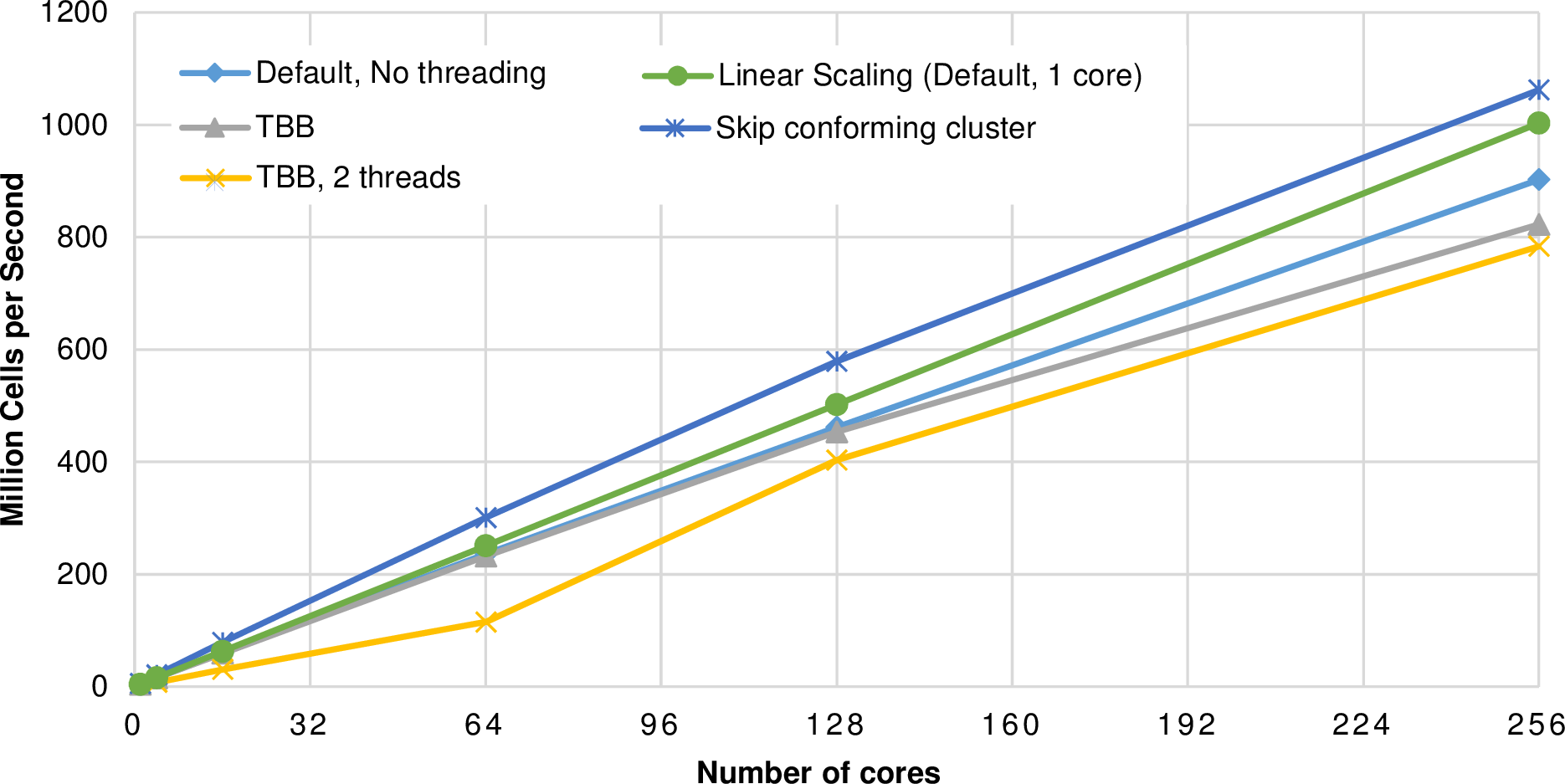
Figure 5.37: Strong scalability on MAC cluster for different parallelization models and
workload. The default method is based on the massive-splitting cluster generation.
Based on the distributed-memory extensions, we executed benchmarks on a small-scale system with up to 256 cores and large-scale system with thousands of cores. Compared to higher-order spatial discretization schemes, a finite-volume discretization leads to larger time steps due to a larger CFL condition and thus more requirements on load-balancing. Therefore, we used a finite-volume simulation with the SWE and the Rusanov flux solver. The scenario was set up with a radial dam break scenario on a quad-shaped domain. All computations are done in single precision.
We conducted small-scale scalability studies on the MAC cluster test platform Intel (see Appendix A.2.3). The initial refinement depth was set to 22 with 8 additional refinement levels for dynamically adaptive mesh refinement. With this fixed problem size, we compute a strong scalability problem.
The dynamic cluster generation is controlled by a massive-splitting method with a split threshold of 4096. Cluster-based load balancing, grid adaptivity traversals and cluster generations are executed between each simulation time step. The cell throughput is given in Fig. 5.37 on up to 256 cores for different parallelization models and optimization activated. The linear scalability is based on a single-core execution of the default massive-splitting cluster generation. Applying our optimization with the conforming-cluster skipping algorithm (see Sec. 5.8.2 and “Skip conforming cluster” in the plot), we generate robust improvements with this algorithmic optimization also on distributed-memory systems.
The TBB threading has a clear overhead compared to our non-threaded version. We account for this by the relatively small computational amount in each cluster and by the additional requirement of a thread-safe MPI libary. However, the drop in performance comparing the single-threaded and the double-threaded TBB benchmark is below 5% for the strong scalability on 256 cores.
We conducted the large-scale scalability studies with several strong scaling benchmarks on the SuperMUC.
For cluster generation, we used a massive-splitting with a threshold size of 32768. We tested different initial refinement depths d = {24,26,28} with up to a = 8 additional dynamically adaptive refinement depths and executed 100 time steps with each simulation. The measurement is started after the last adaptivity traversals and until no further cluster migrations are requested.
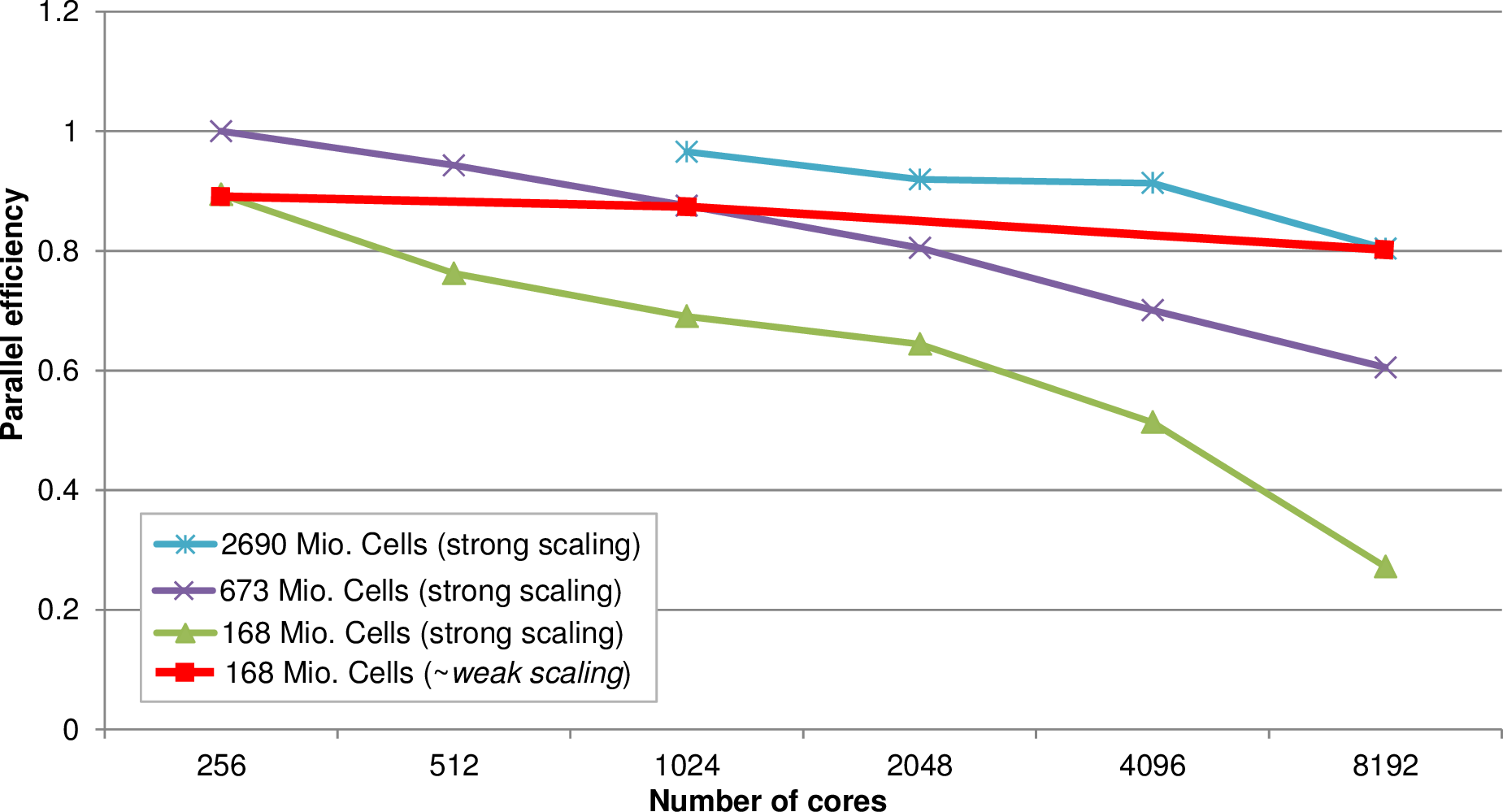
In this benchmark, we only migrated clusters to the next or previous ranks based on the parallel MPI prefix sum over the workload, see [HKR+12] for further information. The results for different initial problem sizes are given in Fig. 5.38. The baseline is given with the simulation on 256 cores, an initial refinement depth of 26 and up to 8 allowed refinement levels. This baseline has a throughput of 1122.76 mio. cells per second.
The simulation with the smaller problem size resulted in worse scalability for a high number of
cores. We account for that by considering the cluster threshold size of 32768. This leads
to  ≈ 0.626 clusters in average per rank and, hence, accounts for the dropdown
in scalability due to severe load imbalances. Smaller cluster sizes or using a range-based
splitting (see Sec. 5.6.2) are expected to improve the scalability and is part of our ongoing
research.
≈ 0.626 clusters in average per rank and, hence, accounts for the dropdown
in scalability due to severe load imbalances. Smaller cluster sizes or using a range-based
splitting (see Sec. 5.6.2) are expected to improve the scalability and is part of our ongoing
research.
Executing the simulation with 2690 million cells was not possible on less cores than 1024 cores due to memory requirements exceeding the physically available memory per compute node. We expect that this can be overcomed by reducing the additional paddings for the prospective stack allocations (see Sec. 4.10.6). However, executing problems of this size on such a relatively small number of cores would never allow computing entire simulation runs due to the high workload and thus very long computation time per core. Therefore we did not further investigate such workloads per core.
Considering weak scaling, the efficiency is still above 90% for 8192 cores with the baseline at 256 cores.